
Most Frequent Subtree Sum
Given the root of a binary tree, return the most frequent subtree sum. If there is a tie, return all the values with the highest frequency in any order.
The subtree sum of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
Example 1:
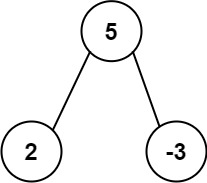
Input: root = [5,2,-3] Output: [2,-3,4]
Example 2:
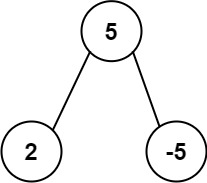
Input: root = [5,2,-5] Output: [2]
Constraints:
- The number of nodes in the tree is in the range
[1, 104]. -105 <= Node.val <= 105
On This Page
Also Explore
DSA Questions
Keyboard Row
DSA Questions
Find Mode in Binary Search Tree
DSA Questions
IPO
DSA Questions
Next Greater Element II
DSA Questions
Base 7
DSA Questions
The Maze II
DSA Questions
Relative Ranks
DSA Questions
Perfect Number
DSA Questions
Most Frequent Subtree Sum
DSA Questions
Fibonacci Number
DSA Questions
Inorder Successor in BST II
DSA Questions
Game Play Analysis I
DSA Questions
Game Play Analysis II
DSA Questions
Find Bottom Left Tree Value
DSA Questions
Freedom Trail
DSA Questions
Find Largest Value in Each Tree Row
DSA Questions