
Find Elements in a Contaminated Binary Tree
Given a binary tree with the following rules:
root.val == 0- For any
treeNode:- If
treeNode.valhas a valuexandtreeNode.left != null, thentreeNode.left.val == 2 * x + 1 - If
treeNode.valhas a valuexandtreeNode.right != null, thentreeNode.right.val == 2 * x + 2
- If
Now the binary tree is contaminated, which means all treeNode.val have been changed to -1.
Implement the FindElements class:
FindElements(TreeNode* root)Initializes the object with a contaminated binary tree and recovers it.bool find(int target)Returnstrueif thetargetvalue exists in the recovered binary tree.
Example 1:
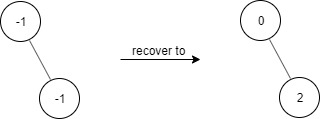
Input ["FindElements","find","find"] [[[-1,null,-1]],[1],[2]] Output [null,false,true] Explanation FindElements findElements = new FindElements([-1,null,-1]); findElements.find(1); // return False findElements.find(2); // return True
Example 2:
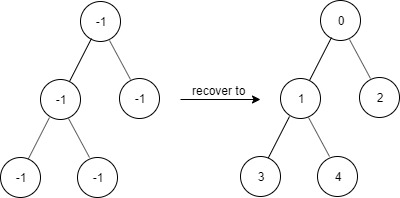
Input ["FindElements","find","find","find"] [[[-1,-1,-1,-1,-1]],[1],[3],[5]] Output [null,true,true,false] Explanation FindElements findElements = new FindElements([-1,-1,-1,-1,-1]); findElements.find(1); // return True findElements.find(3); // return True findElements.find(5); // return False
Example 3:
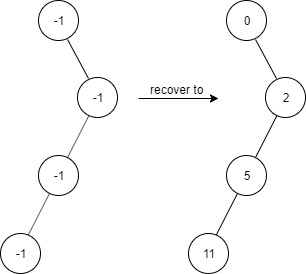
Input ["FindElements","find","find","find","find"] [[[-1,null,-1,-1,null,-1]],[2],[3],[4],[5]] Output [null,true,false,false,true] Explanation FindElements findElements = new FindElements([-1,null,-1,-1,null,-1]); findElements.find(2); // return True findElements.find(3); // return False findElements.find(4); // return False findElements.find(5); // return True
Constraints:
TreeNode.val == -1- The height of the binary tree is less than or equal to
20 - The total number of nodes is between
[1, 104] - Total calls of
find()is between[1, 104] 0 <= target <= 106
On This Page
Also Explore
DSA Questions
Reconstruct a 2-Row Binary Matrix
DSA Questions
Number of Closed Islands
DSA Questions
Maximum Score Words Formed by Letters
DSA Questions
Encode Number
DSA Questions
Smallest Common Region
DSA Questions
Synonymous Sentences
DSA Questions
Handshakes That Don't Cross
DSA Questions
Shift 2D Grid
DSA Questions
Find Elements in a Contaminated Binary Tree
DSA Questions
Greatest Sum Divisible by Three
DSA Questions
Minimum Moves to Move a Box to Their Target Location
DSA Questions
Page Recommendations
DSA Questions
Print Immutable Linked List in Reverse
DSA Questions
Minimum Time Visiting All Points
DSA Questions
Count Servers that Communicate
DSA Questions