
Number of Flowers in Full Bloom
You are given a 0-indexed 2D integer array flowers, where flowers[i] = [starti, endi] means the ith flower will be in full bloom from starti to endi (inclusive). You are also given a 0-indexed integer array people of size n, where people[i] is the time that the ith person will arrive to see the flowers.
Return an integer array answer of size n, where answer[i] is the number of flowers that are in full bloom when the ith person arrives.
Example 1:
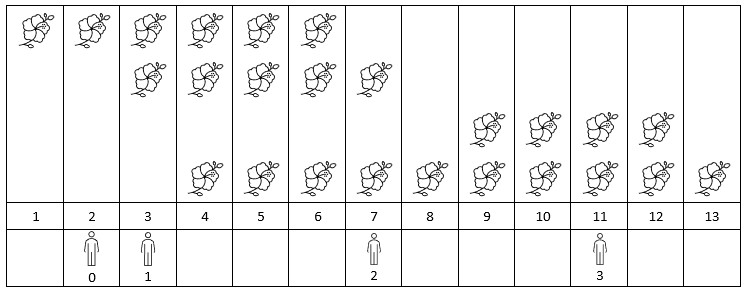
Input: flowers = [[1,6],[3,7],[9,12],[4,13]], people = [2,3,7,11] Output: [1,2,2,2] Explanation: The figure above shows the times when the flowers are in full bloom and when the people arrive. For each person, we return the number of flowers in full bloom during their arrival.
Example 2:
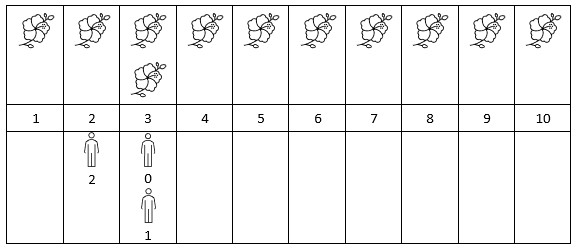
Input: flowers = [[1,10],[3,3]], people = [3,3,2] Output: [2,2,1] Explanation: The figure above shows the times when the flowers are in full bloom and when the people arrive. For each person, we return the number of flowers in full bloom during their arrival.
Constraints:
1 <= flowers.length <= 5 * 104flowers[i].length == 21 <= starti <= endi <= 1091 <= people.length <= 5 * 1041 <= people[i] <= 109
On This Page
Also Explore
DSA Questions
Calculate Digit Sum of a String
DSA Questions
Minimum Rounds to Complete All Tasks
DSA Questions
Maximum Trailing Zeros in a Cornered Path
DSA Questions
Longest Path With Different Adjacent Characters
DSA Questions
Maximum Cost of Trip With K Highways
DSA Questions
Intersection of Multiple Arrays
DSA Questions
Count Lattice Points Inside a Circle
DSA Questions
Count Number of Rectangles Containing Each Point
DSA Questions
Number of Flowers in Full Bloom
DSA Questions
Dynamic Pivoting of a Table
DSA Questions
Dynamic Unpivoting of a Table
DSA Questions
Design Video Sharing Platform
DSA Questions
Count Prefixes of a Given String
DSA Questions
Minimum Average Difference
DSA Questions
Count Unguarded Cells in the Grid
DSA Questions
Escape the Spreading Fire
DSA Questions