
Longest Subsequence Repeated k Times
You are given a string s of length n, and an integer k. You are tasked to find the longest subsequence repeated k times in string s.
A subsequence is a string that can be derived from another string by deleting some or no characters without changing the order of the remaining characters.
A subsequence seq is repeated k times in the string s if seq * k is a subsequence of s, where seq * k represents a string constructed by concatenating seq k times.
- For example,
"bba"is repeated2times in the string"bababcba", because the string"bbabba", constructed by concatenating"bba"2times, is a subsequence of the string"bababcba".
Return the longest subsequence repeated k times in string s. If multiple such subsequences are found, return the lexicographically largest one. If there is no such subsequence, return an empty string.
Example 1:
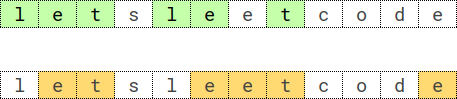
Input: s = "letsleetcode", k = 2 Output: "let" Explanation: There are two longest subsequences repeated 2 times: "let" and "ete". "let" is the lexicographically largest one.
Example 2:
Input: s = "bb", k = 2 Output: "b" Explanation: The longest subsequence repeated 2 times is "b".
Example 3:
Input: s = "ab", k = 2 Output: "" Explanation: There is no subsequence repeated 2 times. Empty string is returned.
Constraints:
n == s.length2 <= n, k <= 20002 <= n < k * 8sconsists of lowercase English letters.
On This Page
Also Explore
DSA Questions
Count Number of Pairs With Absolute Difference K
DSA Questions
Find Original Array From Doubled Array
DSA Questions
Maximum Earnings From Taxi
DSA Questions
Final Value of Variable After Performing Operations
DSA Questions
Sum of Beauty in the Array
DSA Questions
Detect Squares
DSA Questions
Longest Subsequence Repeated k Times
DSA Questions
Average Height of Buildings in Each Segment
DSA Questions
Maximum Difference Between Increasing Elements
DSA Questions
Grid Game
DSA Questions
Check if Word Can Be Placed In Crossword
DSA Questions
The Score of Students Solving Math Expression
DSA Questions
Number of Accounts That Did Not Stream
DSA Questions
Brightest Position on Street
DSA Questions