
Count Pairs Of Nodes
You are given an undirected graph defined by an integer n, the number of nodes, and a 2D integer array edges, the edges in the graph, where edges[i] = [ui, vi] indicates that there is an undirected edge between ui and vi. You are also given an integer array queries.
Let incident(a, b) be defined as the number of edges that are connected to either node a or b.
The answer to the jth query is the number of pairs of nodes (a, b) that satisfy both of the following conditions:
a < bincident(a, b) > queries[j]
Return an array answers such that answers.length == queries.length and answers[j] is the answer of the jth query.
Note that there can be multiple edges between the same two nodes.
Example 1:
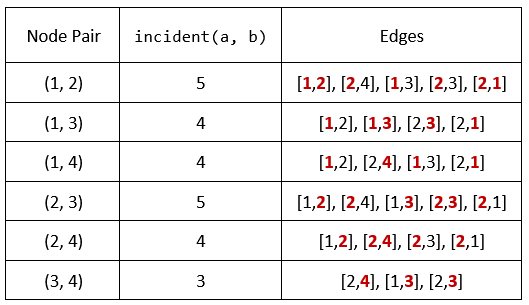
Input: n = 4, edges = [[1,2],[2,4],[1,3],[2,3],[2,1]], queries = [2,3] Output: [6,5] Explanation: The calculations for incident(a, b) are shown in the table above. The answers for each of the queries are as follows: - answers[0] = 6. All the pairs have an incident(a, b) value greater than 2. - answers[1] = 5. All the pairs except (3, 4) have an incident(a, b) value greater than 3.
Example 2:
Input: n = 5, edges = [[1,5],[1,5],[3,4],[2,5],[1,3],[5,1],[2,3],[2,5]], queries = [1,2,3,4,5] Output: [10,10,9,8,6]
Constraints:
2 <= n <= 2 * 1041 <= edges.length <= 1051 <= ui, vi <= nui != vi1 <= queries.length <= 200 <= queries[j] < edges.length
On This Page
Also Explore
DSA Questions
Closest Dessert Cost
DSA Questions
Equal Sum Arrays With Minimum Number of Operations
DSA Questions
Car Fleet II
DSA Questions
Product's Price for Each Store
DSA Questions
Shortest Path in a Hidden Grid
DSA Questions
Check if Number is a Sum of Powers of Three
DSA Questions
Sum of Beauty of All Substrings
DSA Questions
Count Pairs Of Nodes
DSA Questions
Grand Slam Titles
DSA Questions
Minimum Elements to Add to Form a Given Sum
DSA Questions
Number of Restricted Paths From First to Last Node
DSA Questions
Make the XOR of All Segments Equal to Zero
DSA Questions
Maximize the Beauty of the Garden
DSA Questions
Primary Department for Each Employee
DSA Questions