
Remove Duplicates from Sorted List
Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
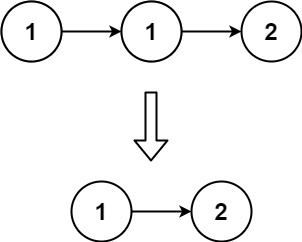
Input: head = [1,1,2] Output: [1,2]
Example 2:
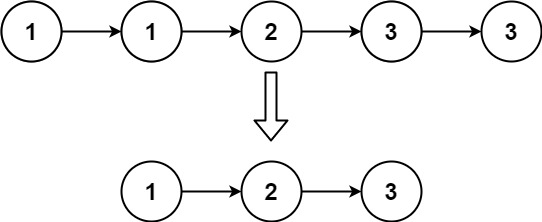
Input: head = [1,1,2,3,3] Output: [1,2,3]
Constraints:
- The number of nodes in the list is in the range
[0, 300]. -100 <= Node.val <= 100- The list is guaranteed to be sorted in ascending order.
On This Page
Also Explore
DSA Questions
Sort Colors
DSA Questions
Minimum Window Substring
DSA Questions
Combinations
DSA Questions
Subsets
DSA Questions
Word Search
DSA Questions
Remove Duplicates from Sorted Array II
DSA Questions
Search in Rotated Sorted Array II
DSA Questions
Remove Duplicates from Sorted List II
DSA Questions
Remove Duplicates from Sorted List
DSA Questions
Largest Rectangle in Histogram
DSA Questions
Maximal Rectangle
DSA Questions
Partition List
DSA Questions
Scramble String
DSA Questions
Merge Sorted Array
DSA Questions
Gray Code
DSA Questions
Subsets II
DSA Questions